Cukup bosen ya belakangan banyak posting tentang digital marketing maupun SEO website, kali ini kita akan bahas tentang pemrograman, khususnya pemrograman, yaitu Python, beberapa tahun ke belakang, saya lebih sering menggunakan python, sesekali Javascript, itu juga sebatas jquery dan react.js untuk beberapa project.
Biasanya sering digunakan dalam kasus Big Data, diatas saya sebutkan menjalankan fungsi yang berkaitan, contohnya adalah filter() map() hingga reduce() ini adalah built in function yang kegunaannya untuk men-generate data yaitu map() lalu untuk mengurangi atau membagi secara berurutan, yaitu reduce() sedangkan filter() digunakan untuk memilah hasil yang sesuai kriteria jalannya program.
Penggunaan lambda ini sangatlah sederhana, yaitu cukup dengan
lambda argumen: ekspresi
Mari kita ambil contoh dalam program mencari bilangan bulat genap yang diberikan di sebuah list.
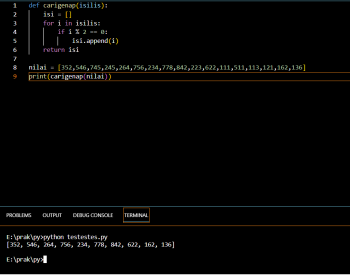
def carigenap(isilis):
isi = []
for i in isilis:
if i % 2 == 0:
isi.append(i)
return isi
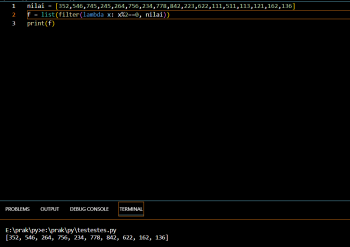
nilai = [352,546,745,245,264,756,234,778,842,223,622,111,511,113,121,162,136]
print(carigenap(nilai))
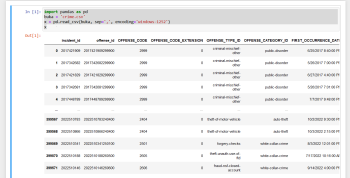
Bandingkan dengan
nilai = [352,546,745,245,264,756,234,778,842,223,622,111,511,113,121,162,136]
f = list(filter(map(lambda x: x % 2 == 0, nilai)))
print(f)
Tentu lebih sederhana Lambda function, tapi dalam penggunaannya tentu bergantung pada kasus yang dihadapi si programmer, tidak serta merta Lambda lebih mudah, lalu memakainya dalam views.py Django, jelas tidak mungkin toh, mari coba lagi.
kata = ['Indonesia tanah ku yang permai', 'kan ku puja sepanjang masa']
m = list(map(lambda x: x[0] + x[1], kata))
print(m)
def baca(kata):
mata = kata[0][:2],kata[1][:2]
return mata
kata = ['Indonesia tanah ku yang permai', 'kan ku puja sepanjang masa']
print(baca(kata))
Sayangnya sudah bisa ditebak, bahwa lambda tidak bisa digunakan lagi, saat dibawahnya akan ada fungsi lain yang membutuhkannya, sehingga harus tetap men define fungsi tersebut, lalu seperti apakah kegunaan Lambda di kasus nyata ?
Saya ambil contoh kasus ini ya, jadi download datasetsnya di kaggle.com/datasets/paultimothymooney/denver-crime-data/code?resource=download context nya kita akan mempelajari laporan data kriminalitas, dan menganalis, seberapa sering terjadinya kejahatan di dataset tersebut dan di jam berapa saja ?
Pertama, impor pandas lalu baca
import pandas as pd
buka = 'crime.csv'
x = pd.read_csv(buka, sep=',', encoding='windows-1252')
x
Kalau kita lihat SS dibawah ini, terlihat bahwa di column FIRST_OCCURANCE_DATE, terjadinya kriminalitas, jadi kita gunakan slice dulu
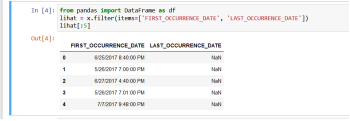
from pandas import DataFrame as df
lihat = x.filter(items=['FIRST_OCCURRENCE_DATE', 'LAST_OCCURRENCE_DATE'])
lihat[:5]

Gunakan juga konversi hasil data ke list, dengan cara
perhatikan = lihat.values.tolist()
Diatas kelihatan sekali bahwa terdapat NaN atau data yang tidak terbaca, biasanya tidak terinput dengan benar, atau memang datanya kosong, maka sudah tentu ini akan menghalangi proses analisis, sehingga perlu dilakukan data cleaning terlebih dulu, biasanya menjadikannya mean atau rata-rata, bisa juga memfilter, mana-mana saja yang tidak bernilai NaN, di sinilah Lambda digunakan.
import math
dataklining = list(filter(lambda x: str(x[1]) != 'nan', perhatikan))
dataklining[:5]
Supaya lebih mudah, kita konversi lagi, karena kita butuh string
from datetime import datetime
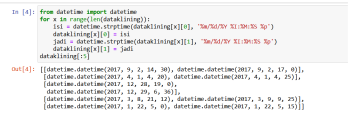
for x in range(len(dataklining)):
isi = datetime.strptime(dataklining[x][0], '%m/%d/%Y %I:%M:%S %p')
dataklining[x][0] = isi
jadi = datetime.strptime(dataklining[x][1], '%m/%d/%Y %I:%M:%S %p')
dataklining[x][1] = jadi
dataklining[:5]
Sekarang kita generate lagi, menjadi dua waktu di satuan hari, yaitu menggunakan map()
import numpy as np
waktu = list(map(lambda m: (m[1]-m[0]).days + (m[1]-m[0]).seconds//86400, dataklining))
waktu1 = np.array(waktu)
waktu1.mean()
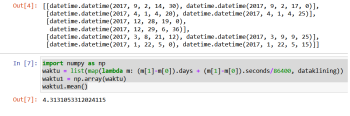
Jadi kalau di lihat, lama kejadian kriminalitas di kota Denver, didapati bahwa 4.3 hari, nah setelah itu kita harus cari tahu lagi, di jam berapa aja sih, kejahatan ini paling sering kejadian, di sini kita pakai .hour dari datetime.
from operator import itemgetter
cari = {}
for i in range(len(dataklining)):
if dataklining[i][0].hour in cari:
cari[dataklining[i][0].hour]+= 1
else:
cari[dataklining[i][0].hour] = 1
urutin = sorted(cari.items(), key=itemgetter(1), reverse=True)
print(urutin, end='')
Jadi kalau di lihat, lama kejadian kriminalitas di kota Denver, didapati bahwa 4.3 hari, nah setelah itu kita harus cari tahu lagi
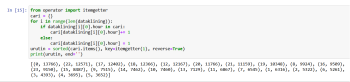
Diatas, kita buat perulangan, lalu simpan ke dictionary variabel cari, dengan mencari juga di kondisi yang dibuat indeks ke 0 di list itu, kemudian di urutkan secara descending, ambil items() saja dari dictionarynya, lalu itemgetter itu atribut ya operator python, dimana ini juga bisa jadi methods untuk mengurutkan element maupun tipe datanya.
Setelah ketik enter, maka tampillah hasilnya, bahwa kejahatan di Denver seringkali terjadi terutama pada pukul 12 malam, jam 10 malam menempati urutan ke-2, sisanya bahkan sore, seperti jam 5, jam 6 bahkan siang bolong, terus jam 8 malam, jam 9 malam dan jam 7 juga.
Wow, terlepas ini lagi belajar data analisis yang nantinya bisa dikembangkan menjadi materi market research sederhana dengan Lambda Function, kaget juga ya, angka kekerasan dan kejahatan di sana sangatlah tinggi, hampir tiap jam sih ini.
Baiklah, semoga bahasan yang berbeda kali ini bisa memberi wawasan, tentang bagaimana Lambda function bisa bekerja, dan cara pengoperasiannya.